バージョン情報
- Elasticsearch 6.3
やりたいこと
Elasticsearchで日本語の全文検索エンジンを構築する時に、日本語の形態素分析のプラグインとしてkuromojiを使うことが多いと思うのだけれど、そのkuromojiがどのように単語分割してインデックスに保存しているのか知りたいと思った。
kuromojiの単語分割の結果だけであれば、それを見ることは次のサイトから確認できる。
https://www.atilika.org/
でも実際のインデックスでは、検索精度を向上させるために、単語分割した結果を色々なフィルタに通して変形したり、不要な品詞を除去したりしていると思う。
そのフィルタを通した最終的な単語達がなんなのかを取得したい。
Term Vectors API
そんな時に使えるのがTerm Vectors API。
使い方はGET系のAPIなのでめっちゃ簡単で、次の様なリクエストを実行するだけ。
GET /posts/_doc/1/_termvectors?fields=title
実際にやってみる
kuromoji_tokenizerで単語分割し、kuromoji_part_of_speechを使って検索に不要な品詞を除去したpostsというインデックスがあるとする。
このインデックスに対して吾輩は猫である。という文章を登録する。
吾輩は猫である。をさっきのサイトでkuromojiの形態素分析をした結果は次になる。
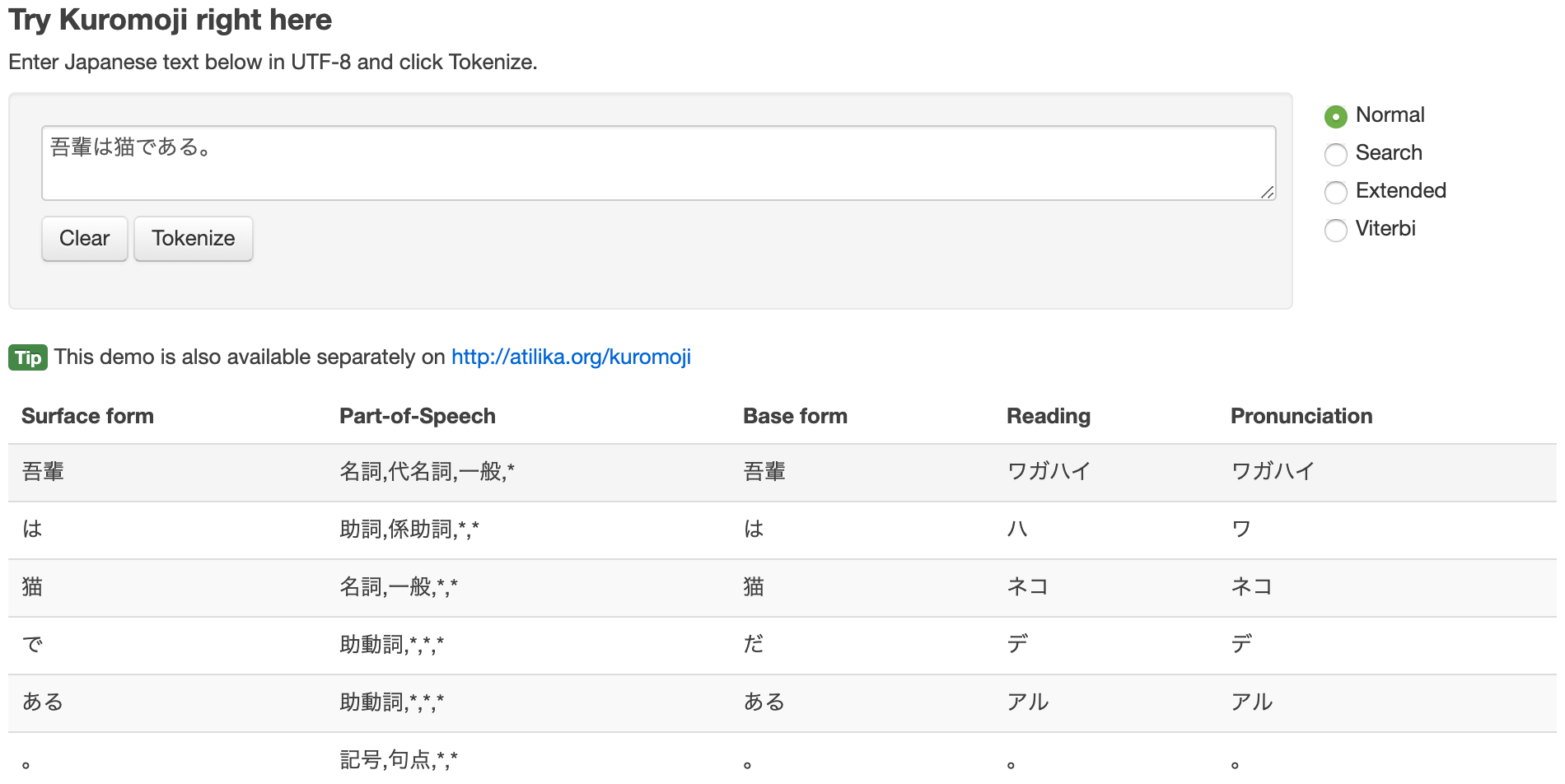
助詞のはとか句読点の。とか、検索に不要そうな単語もならんでいますね。
これがindex上ではどのようになっているかTerm Vectors APIを使用して確認してみるとどうなるか。
ただ、普通にリクエストすると、文字の位置の情報とか色々と今回の調査に対しては不要な情報も含まれてくるので、不要な内容をオプションによりfalseにしたjsonを送りつけると、レスポンスがシンプルになる。
GET /posts/_doc/1/_termvectors
{
"fields" : ["title"],
"offsets" : false,
"positions" : false,
"field_statistics" : false
}
結果は次
{
"_index": "posts",
"_type": "_doc",
"_id": "1",
"_version": 1,
"found": true,
"took": 0,
"term_vectors": {
"title": {
"terms": {
"吾輩": {
"term_freq": 1
},
"猫": {
"term_freq": 1
}
}
}
}
}
kuromoji_part_of_speechによって、検索に不要な単語は除去され、我輩と猫だけがインデックスに保存されていることがわかる。
つまりこのドキュメントは、「我輩」と「猫」で検索された時にヒットすることが確認できる。
終わりに
Term Vector APIの用途ってこれでもいいのかな?
位置の情報なども細かい調査には便利そうなので、活用します!
